Principal Component Analysis (PCA) in Python
A Comprehensive Introduction to PCA with Python
Introduction to Principal Component Analysis (PCA)
Principal Component Analysis (PCA) is a statistical and data analysis technique used to discover and extract structure in a set of data. It is often used to reduce large data sets and to identify important features or characteristics in the data1. PCA is based on the assumption that the features in a set of data are correlated with each other and that a small portion of these features explains most of the variance in the data. The goal of PCA is to create new features that capture as much of the variance and correlation in the data as possible. These new features are called principal components and they can be used to recode and reduce the data.
PCA has many applications, such as reducing the dimensions of image data, analyzing financial data, and analyzing genetic data. It is a useful technique to identify the structure and meaning of data and to better understand and analyze this data2.
How does PCA work?
To perform PCA, the characteristics of the data are first standardized by setting the mean of each characteristic to 0 and the standard deviation to 1. A covariance matrix of the standardized features is then calculated to quantify the correlation between the features. The eigenvectors of this matrix are then calculated and the principal components are represented as linear combinations of the original features3.
Applications of PCA
Principal component analysis (PCA) is applied in many areas of statistics and data analysis. Some applications include:
- Reducing the dimensions of image data: PCA can be used to reduce the number of features in large image datasets without losing important information.
- Analysis of financial data: PCA can be used to study the correlations between different financial market data and to identify important market trends.
- Analysis of genetic data: PCA can be used to study the relationships between different gene variants in large genetic datasets and to discover important patterns and associations4.
A Simple PCA Implementation in Python
Let’s now dive into a simple implementation of PCA in Python.
import numpy as np
from sklearn.decomposition import PCA
# Create sample data
data = np.random.rand(100, 5)
# run PCA
pca = PCA(n_components=3) # Set number of Principal Components
pca.fit(data) # fit PCA
transformed_data = pca.transform(data) # transform sample
# Show transformed data
print(transformed_data)
To visualize the importance of each principal component, we can plot the explained variance:
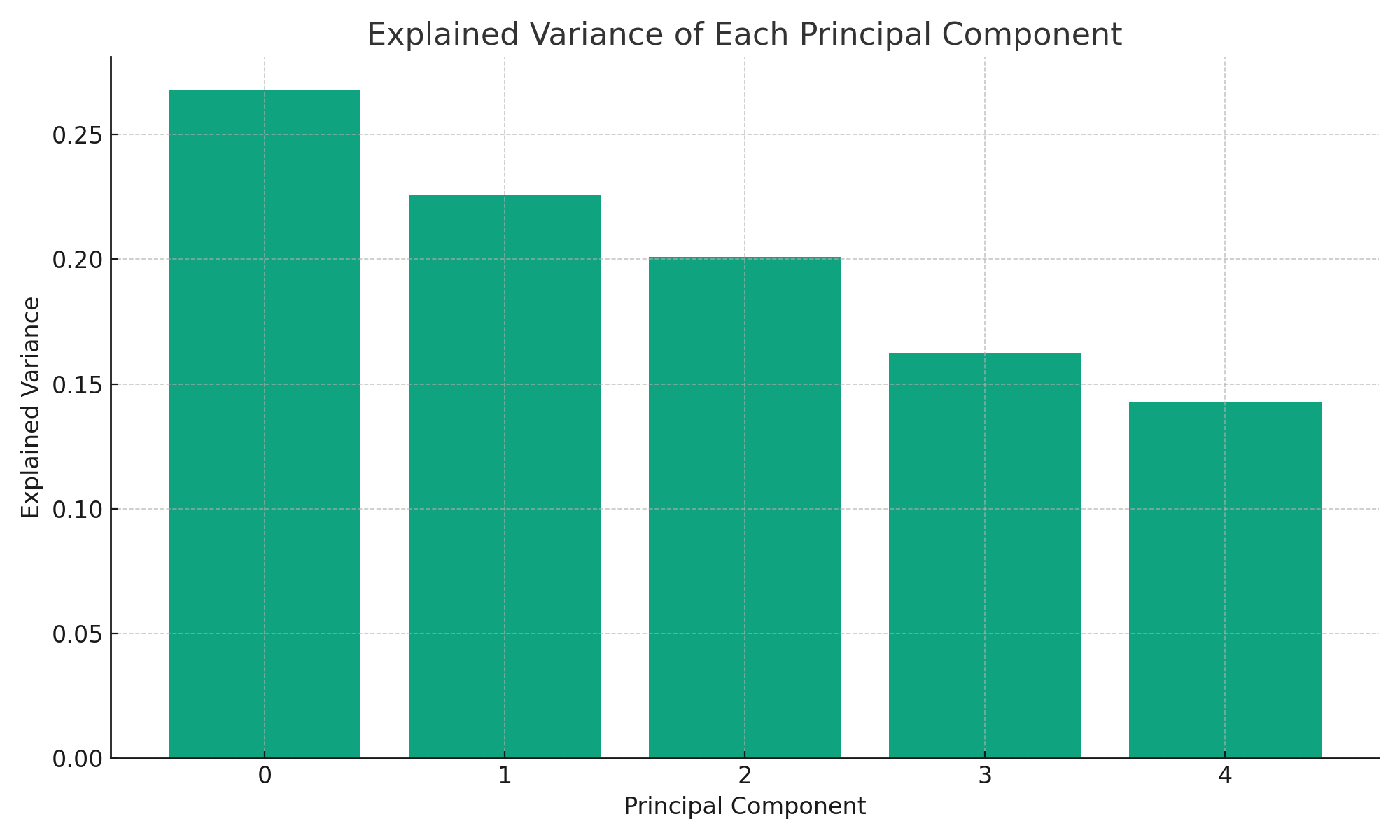
A scatter plot of the first two principal components can provide insights into the data distribution:
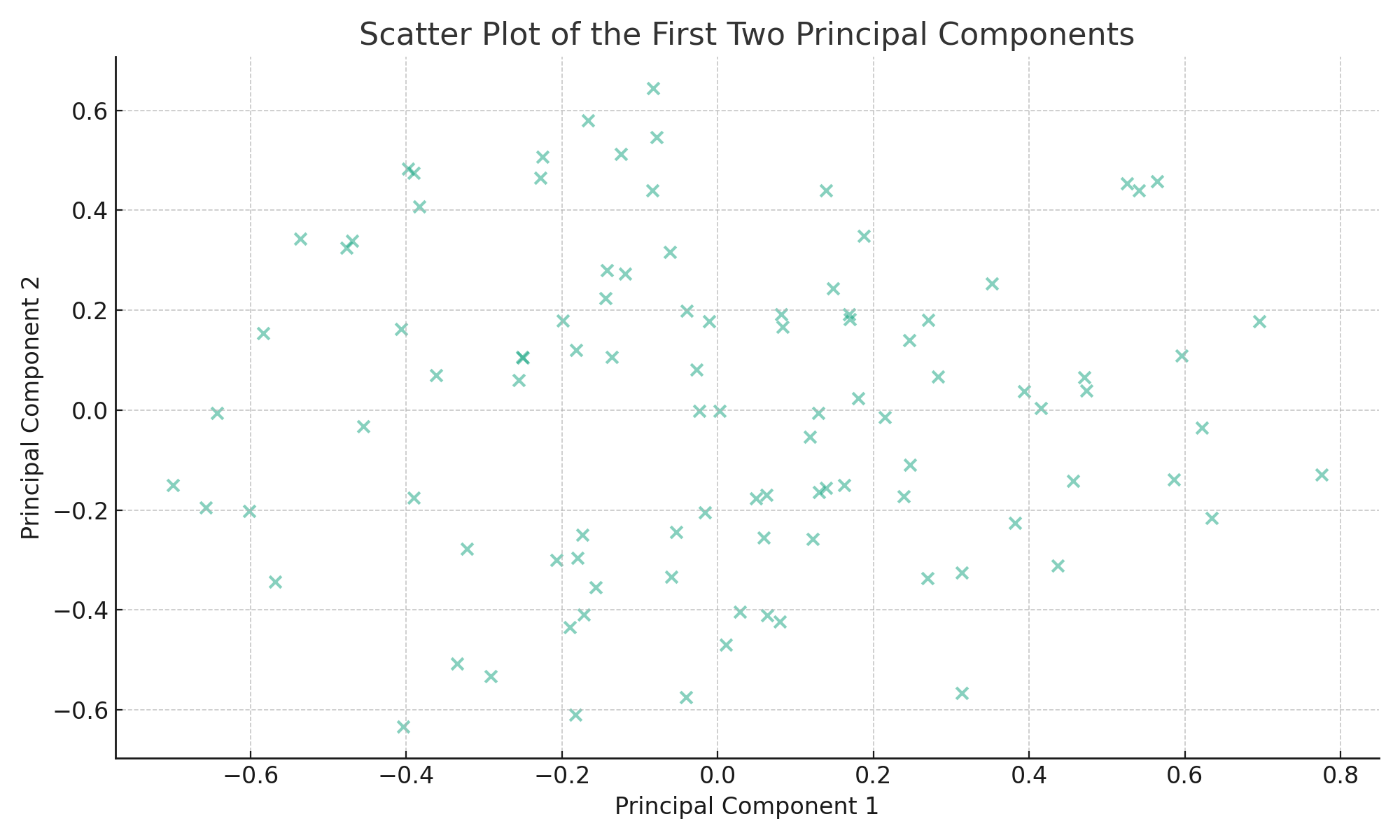
PCA is a powerful tool for data analysis and dimensionality reduction, and understanding its underlying concepts is crucial for effectively applying it in practice5.
Conclusion
PCA is a foundational technique in data analysis and has found its application in numerous domains. By transforming the original features into a set of orthogonal features, PCA helps in identifying the most important features in a dataset, thereby assisting in dimensionality reduction and efficient data analysis.
Smith, L. (2002). A tutorial on Principal Components Analysis. Cornell University, USA. ↩︎
Jolliffe, I. T., & Cadima, J. (2016). Principal component analysis: a review and recent developments. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences, 374(2065), 20150202. ↩︎
Abdi, H., & Williams, L. J. (2010). Principal component analysis. Wiley interdisciplinary reviews: computational statistics, 2(4), 433-459. ↩︎
Ringnér, M. (2008). What is principal component analysis?. Nature biotechnology, 26(3), 303-304. ↩︎
Shlens, J. (2014). A tutorial on principal component analysis. arXiv preprint arXiv:1404.1100. ↩︎
Alexander Maximilian Röser
Senior Consultant @WEPEX
My research interests include Artificial Intelligence, Data Science and Digital Transformation.